
La possibilita’ di accedere ai dati di ricerca di Google ha stimolato notevole interesse in diversi ambiti. Fra questi, quello della previsioni politiche e’ probabilmente quello piu’ recente, mentre in ambito economico, finanziario e medico, la ricerca (accademica e non) ha gia’ ottenuto importanti risultati.
Il motivo principale che ha finora limitato gli sviluppi nell’ambito delle previsioni elettorali e’ sicuramente da attribursi al cosidetto problema dell’Auto-Selezione, piu’ comunemente noto in inglese come Self-Selection Bias: in questo caso, gli individui appartenenti al campione oggetto di analisi non sono scelti in maniera casuale, bensi’ sono essi stessi che decidono di entrare nel campione stesso, in tal modo creando un campione distorto, poco rappresentativo della intera popolazione. Questo purtroppo e’ esattamente quello che succede con GTI, che riporta i dati solo degli individui che effettuano una ricerca su Google, ad esempio per cercare informazioni su un candidato alle prossime elezioni.
Ad esempio, i dati GTI contengono solo un piccolo numero di ricerche di natura politica da parte di persone sopra i 60 anni, che come e’ noto utilizzato internet in modo estremamente limitato (per ovvie ragioni): purtroppo, questo gruppo e’ anche quello che piu’ di tutti va a votare. Similmente, se internet non e’ molto diffuso fra la popolazione locale, la distorsione da auto-selezione del campione risultera’ notevole. Si veda qui per maggiori dettagli e referenze:
Questo problema e’ noto da tempo a chi effettua sondaggi online usando la cosidetta tecnica Computer-assisted web interviewing (CAWI):
Tuttavia, in questo caso,e’ possibile conoscere (approssimativamente) quali gruppi di individui sono sotto-rappresentati e quali sovra-rappresentati, confrontando le caratterische qualitative del campione del sondaggio online con quelle della popolazione, e creando di conseguenza appositi pesi campionari per correggere la distorsione presente nel campione originario del sondaggio. A questo riguardo, si rimanda all’articolo divulgativo pubblicato su Termometro Politico il 09/06/2009 intitolato Sovrastime e sottostime nei sondaggi CAWI, mentre per un maggiore approfondimento si veda questo articolo e questa discussione.
Purtroppo, lavorando con i dati GTI, NON si ha accesso a questo genere di informazioni qualitative, per cui non e’ possibile ri-balanciare i volumi di ricerca per un candidato o un partito politico al fine di avere un campione rappresentativo della popolazione.
Detto questo, ci troviamo quindi di fronte a quattro possibilita’:
- Usare i soli dati GTI: questa opzione attualmente e’ possibile con un numero limitato di elezioni, solo e esclusivamente a carattere nazionale, con un numero di votanti e una penetrazione internet molto elevati. Uno di questi casi sono al momento le elezioni presidenziali USA:


(La media mobile a 14 giorni e’ riportata a soli fini informativi e non e’ stata fatto al riguardo alcun tentativo di trovare il valore ottimale. Chiaramente, un lavoro in tal senso potrebbe ulteriormente migliorare i risultati (per esempio, la media mobile a 3 giorni potrebbe essere un valido candidato). Inoltre, si ricorda che il presidente USA e' eletto in base ai grandi elettori su base statale)
2) Usare i dati GTI, ricalibrandoli usando passate elezioni (eventualmente usando funzioni nonlineari): questa opzione e’ in realta’ un complemento a quella precedente, ma permette di estendere notevolmente il numero di elezioni che possono essere analizzate utilizzando i dati GTI. Tuttavia, per esperienza personale, almeno 1 o 2 milioni di votanti sono richiesti, insieme ad una penetrazione Internet nella popolazione almeno intorno al 50% (o maggiore).
Inoltre, va detto che in alcuni paesi l’espansione di internet e’ talmente veloce, che i pesi calibrati per le diverse forze politiche anche solo 1 o 2 anni prima, possono non andare piu’ bene nelle ultime elezioni analizzate!!!
A mio vedere, questo e’ uno dei maggiori problemi correnti per chi vuole usare dati GTI: tuttavia, va anche detto che col passare del tempo e l’avvicinarsi ad una penetrazione internet intorno al 70%-80% della popolazione, i valori tendono a stabilizzarsi. In questo senso, ci vuole un po’ di pazienza. Per chi pazienza non ha (e ha moooooolto tempo a disposizione), ci sono i modelli a coefficienti variabili…ma questa e’ una altra storia. ^__^
Come detto in altre occasioni, la scelta dei termini di ricerca e’ fondamentale e richiede molta attenzione: per esempio, nel caso si voglia studiare l’andamento di alcuni partiti politici, e’ sempre meglio usare il nome dei partiti senza usare quello dei leader. Inoltre, ho spesso constatato che usare i soli acronimi dei partiti (ad esempio “PSD” invece che “Partido Social Semocrata”, per il partito social democratico portoghese) permette di ottenere stime migliori in varie occasioni. In questo ultimo caso, tuttavia, la scelta dei termini e’ ancora piu’ cruciale e fonte di possibili errori. Prendiamo per esempio il “Bloco de Esquerda” portoghese che viene spesso richiamato con l’acronimo “BE”: purtroppo se mettiamo “BE” all’interno di GTI per il Portogallo, i termini di ricerca maggiormente associati con “BE” sono in ordine decrescente: “to be”, “you”,”be you”,”lyrics”,”be on”, “you to be”, “wanna be”, “be free”, “be happy”, “let it be”, “saidia”, “hotel be live”, “be live”, “psd”, “ps”. Inutile dire, che qualunque numero ottenuto con questi dati non avrebbe alcun senso.
Si riportano sotto i dati GTI ri-calibrati in base a elezioni passate, la media a 7 giorni di questi dati e i risultati finali (le linee orizzontali) per i cinque principali partiti portoghesi nelle ultime elezioni politiche tenutesi il 05/06/2011:




Si ricorda che la media mobile a 7 giorni e’ riportata a soli fini informativi e non e’ stata fatto al riguardo alcun tentativo di trovare il valore ottimale. Chiaramente, un lavoro in tal senso potrebbe ulteriormente migliorare i risultati (per esempio, la media mobile a 3 giorni potrebbe essere un valido candidato).
Riportiamo infine l’analisi fatta al tempo delle elezioni presidenziali portoghesi tenutesi il 23/01/2011:


- Usare i dati GTI solo per vedere le tendenze in atto, eventualmente ponderando i dati con alcuni fattori di correzione giusto per avere un idea di massima sulla situazione reale.
Nel caso in cui il numero dei votanti sia piuttosto basso (meno di 1 or 2 milioni votanti) e/o la penetrazione internet altrettanto bassa (sotto il 50%), il miglior utilizzo che si puo’ fare con i dati GTI e’ sicuramente quello di osservare le tendenze in atto, praticamente in tempo reale, senza pero’ voler ottenere dei numeri per misurare le forze politiche in campo. In questo caso, la distorsione dovuta all’auto-selezione puo’ essere talmente elevata da invalidare qualunque analisi statistica.Tuttavia, se si parte dal presupposto di non avere alcuna pretesa numerica, si puo’ cercare di ponderare i dati GTI per avere un’idea di massima (seppure molto grezza) sulla situazione reale: una operazione di questo genere puo’ avere senso per valutare l’andamento di una specifica campagna mediatica a favore di un partito, in termini ovviamente molto generici e consci che i numeri reali possono essere diversi.
In questo caso si possono adottare due approcci:
3-a) Ponderare i dati GTI con l’ultima elezione passata (sapendo pero’ che sono molto instabili, e in ogni caso molto approssimativi, a causa del problema dell’auto selezione)
3-b) Cercare di aggiustare i dati GTI incrociando i dati audiweb e Itanes (questi ultimi forniscono le percentuali ottenute dai maggiori partiti nelle elezioni del 2008per una serie di classificazioni socio demografiche). Si veda qui su TP un bel esempio su come incrociare questi dati. Riporto sotto la loro Figura 1 per semplicita’:
Tuttavia, va detto che mentre questo ultimo approccio e’ sicuramente molto utile per valutare le sovrastime e sottostime di un sondaggio CAWI, la sua utilita’ per eventualmente aggiustare i dati GTI non e’ nota (io non l’ho mai provato e non conosco lavori al riguardo). Inoltre, i fattori di ponderazione che si possono ricavare da una tale operazione potrebbero risultare gia’ vecchi, in quanto basati sulle elezioni 2008 (si veda qui e qui per capire come il mercato internet si sta evolvendo in Italia negli ultimi anni) . Infine, mentre nei sondaggi CAWI si conosce il numero di individui nel sondaggio e le sue caratteristiche qualitative, con i dati GTI non si hanno tali informazioni, e quindi l’applicazione di eventuale fattori di ponderazione a dati cosi’ aggregati sarebbe alquanto dubbia. Se c’e’ qualcuno che ci vuole provare ben venga: a me l’avevano consigliato tempo fa per curiosita’,ma per mancanza di tempo e per i dubbi sopra discussi,non l’ho mai provato.










Invece, come esempio del caso 3-a) sopra discusso, riporto sotto le analisi svolte con i dati GTI in occasione delle elezioni comunali a Milano e Napoli, dove sono stati eletti i nuovi sindaci e i rispettivi consigli comunali. In entrambi i casi, abbiamo un numero di elettori abbondatemente sotto il milione e la penetrazione internet sotto il 50% (seppure molto maggiore a Milano, rispetto che a Napoli).
Cominciamo con Milano:
[I risultati del primo turno elettorale per i due candidati, cosi' come i dati GTI antecedenti al primo turno, sono stati standardizzati in modo tale da sommare a 100 e renderli comparabili con i dati del secondo turno]

E' interessante notare come i valori previsti con i dati GTI (ri-calibrati con le elezioni passate) per il primo turno siano stati estremamente vicini ai risultati reali: ammetto che io stesso sono rimasto positivamente sorpreso dalla loro precisione in questo caso.
Tuttavia, passato il primo turno elettorale, i sostenitori di Pisapia (cosi' come semplice curiosi) hanno determinato un forte aumento nel volume di ricerca del termine "Pisapia" rispetto al termine "Moratti", in realtà solo parzialmente collegato con le reali intenzioni di voto poi espresse nel secondo turno: alla fine del secondo turno, infatti, se da un lato le tendenze di fondo per i due candidati sono risultate corrette, dall'altro lato ogni stima numerica e' risultata fortemente sovra-stimata nel caso di Pisapia di circa 10/15 punti %, e altrettanto sotto-stimata nel caso del candidato Moratti. In un certo senso, si e' avuto un caso di self-selection bias da manuale di statistica. Questo spiega anche perche' sono sempre stato molto restio a fornire dati numerici in questo caso, in quanto potevano essere notevolmente distorti (come poi e' successo) e privi di valenza statistica. Mi auguro che questo articolo possono chiarire meglio i motivi di un tale comportamento.
Passiamo a Napoli:


In questo caso si e' verificato un comportamento simile a quello osservato per Milano ma, nel caso del secondo turno elettorale, di segno opposto: quindi, nuovamente un'ottima precisione per il primo turno, mentre nel secondo turno a fronte di tendenze elettorali assolutamente corrette (un forte interesse per De Magistris e un calo per Lettieri), si e' osservato una sottostima numerica nel caso del candidato di centro-sinistra e una sovra-stima per quello di centro-destra. E' noto a tutti che le dinamiche elettorali napoletane sono alquanto complesse, e quindi la distorsione da auto-selezione rilevata per il secondo turno e' il risultato di diverse componenti (anche di segno opposto) non facili da separare. Lasciamo ai posteri (e ai curiosi) il compito di svolgere una siffatta analisi ex-post.
- Utilizzare i dati qualitativi proprietari di Google relativi ad ogni singolo utente che ha effettuato una ricerca di tipo politico, in modo tale da trattare i dati di ricerca online come un (grandissimo) sondaggio CAWI e poterli quindi ponderare per renderli rappresentativi della popolazione sottostante. Inoltre usare questi dati per selezionare solo quelle ricerche specifiche relative al candidato/partito preso in considerazione.
Questa opzione e' ovviamente quella che permetterebbe di usare completamente l'enorme potenziale dei dati GTI.
Per dare un idea di quali dati qualitativi si possono utilizzare, riporto sotto i dati demografici riportati da Alexa.com con riferimento agli utenti che frequentano il sito Google.it in relazione alla "general internet population" (purtroppo "Google Trends for websites" non riporta questa informazione .... ^__^):

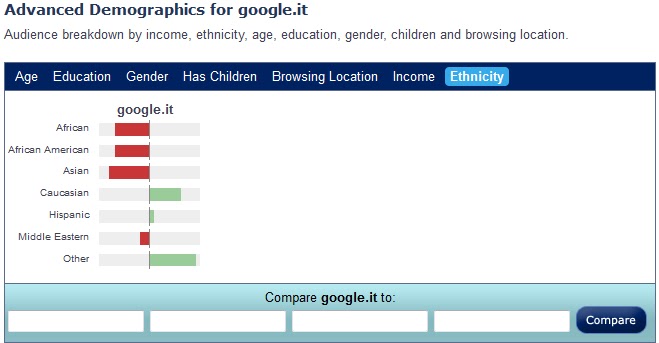
Chiaramente una tale opzione può essere sviluppata solo e esclusivamente con una partecipazione attiva da parte di Google stessa, in quanto i dati qualitativi per ogni singolo utente che ha effettuato una ricerca politica online su GTI (e le singole ricerche) sono proprietari di Google.
Se c'e' qualche responsabile di Google che legge questo articolo e che nutre interesse in questo ambito, vogliamo dire che siamo assolutamente disponibili a condividere e discutere la nostra esperienza sviluppata fino ad ora lavorando con dati GTI.
Gigi Bi
Vi invitiamo a diventare nostri fan su facebook, cliccando qui
Comments